| 在“AI for Science(人工智能驱动的科学研究)”席卷全球的今天,利用机器学习(ML)来预测材料性能、加速配方设计早已成为材料学界的前沿趋势。然而,当AI走进聚合物水凝胶等具有强非线性、高度耦合的软物质领域时,往往会遭遇隐藏的“数据危机”——由于小样本数据中存在平行的重复实验,传统的随机划分数据集极易导致数据泄露(Data Leakage)。这就像让AI在期末考试中做“做过的原题”,虽然账面成绩(测试集性能)极其虚高,可一旦面对全新配方时就会瞬间“现出原形”。 |
针对这一行业痛点,太原理工大学黄棣团队联合相关合作单位,在聚合物领域国际权威期刊《Polymer》上发表了最新研究成果。他们首创了一套抗数据泄露、高泛化性且具备双重可解释性的机器学习闭环工作流。在极具挑战性的小样本条件下,实现了对聚乙烯醇/羟基磷灰石(PVA/HA)复合水凝胶拉伸与压缩模量的精准工程化预测,彻底终结了水凝胶配方设计依赖“盲盒试错”的传统模式。一、 直击痛点:首创“配方分组”GroupKFold,撕下性能虚高面纱
在软物质材料实验中,由于制备和测试工艺的复杂性,同一配方通常需要进行多次平行重复实验。若采用常规的随机切分,这些极度相似的平行样本会被拆分到训练集与测试集两端,造成严重的“数据泄露”。
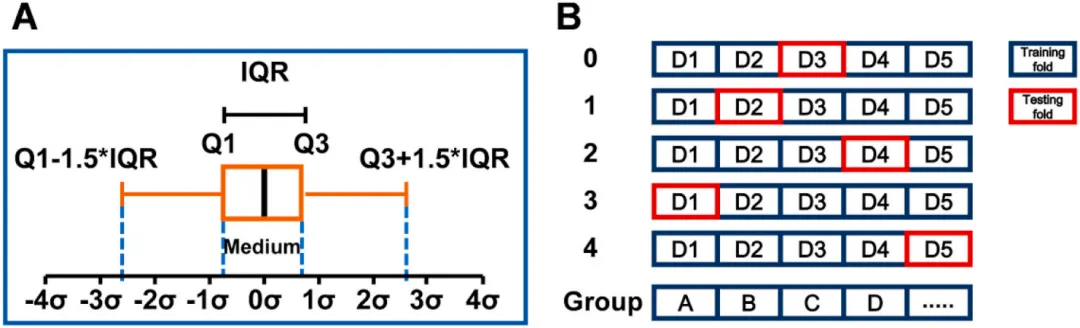
图1 (A) IQR 异常值检测示意图;(B)基于公式分组的GroupKFold(5折)交叉验证方法。
为了给AI搭建一个真正严苛、贴近真实工程盲测的“考场”,黄棣团队从根本上重塑了数据治理体系:
打造高纯度标准化数据集:团队拒绝使用多源、存在系统噪音的文献二手数据,而是采用严格统一的“一锅法”结合冻融循环工艺自制样本。通过科学的四分位距法(IQR)剔除实验中的随机误差和离群点,最终提炼出包含227个拉伸模量(TM)和249个压缩模量(CM)的高质量真实验证数据集。
配方级“物理隔离”验证机制:团队创新性地将“PVA浓度+HA含量+HA粒径+冻融次数”的四维特征组合定义为唯一的GroupID。在进行5折交叉验证时(GroupKFold),强行规定相同GroupID的平行样本必须打包归入同一个 Fold,绝不拆分。这意味着验证集里永远是训练集“一生未见”的崭新配方,从而逼迫AI去真正学习材料背后的物理和化学规律,拒绝任何“死记硬背”。
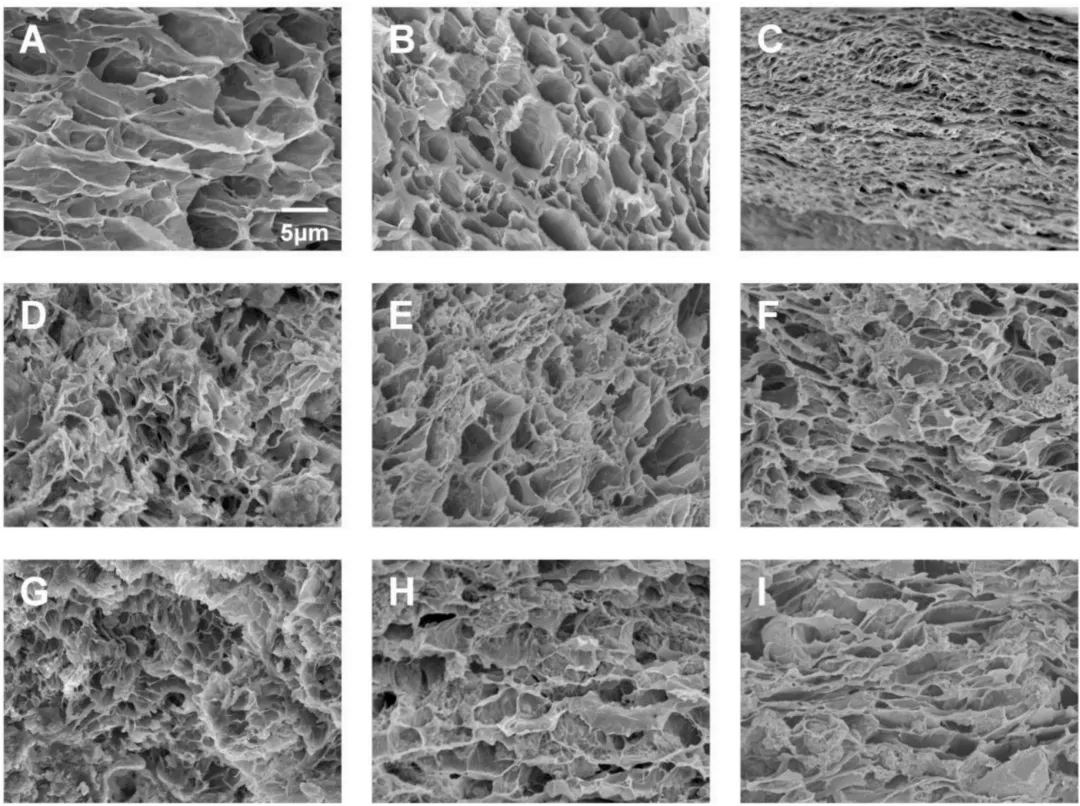
图2(A-C)PVA水凝胶经过1次、3次和5次冻融循环后的SEM图像;(D-F)PVA10HA20 10水凝胶经过相同次数冻融循环后的SEM图像;(G-I)PVA10HA200 10水凝胶经过相同次数冻融循环后的SEM图像。
二、 算法竞技:六大主流ML模型同台PK,XGBoost加冕“双料冠军”
在如此严苛且不含水分的 GroupKFold 评估体系下,团队将六种具有代表性的经典机器学习算法——决策树(DT)、随机森林(RF)、支持向量回归(SVR)、K近邻(KNN)、梯度提升决策树(XGBoost)以及 LightGBM 投入到了同台竞技中:
集成学习展现降维打击:实验表明,得益于 stage-wise 拟合残差的能力,集成树模型在捕捉水凝胶多维高阶非线性交互特征方面表现卓越。
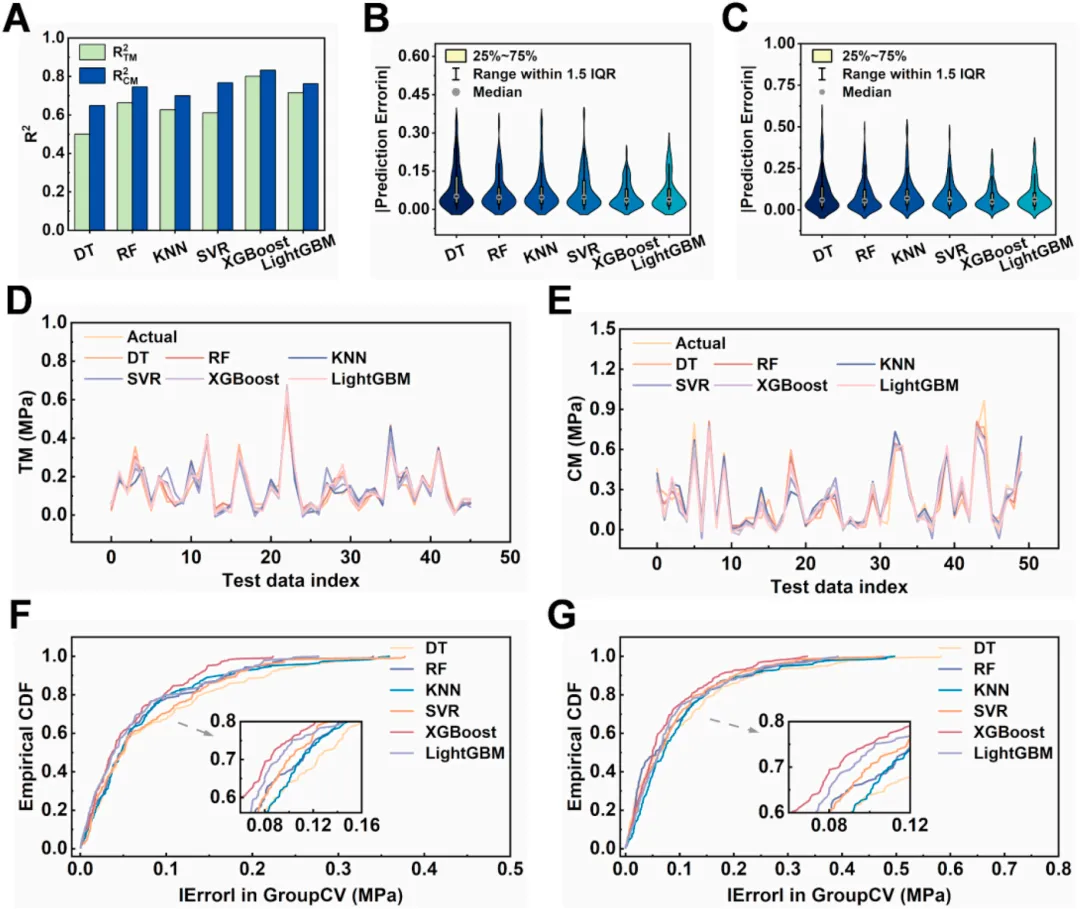
XGBoost斩获最优预测性能:在面对完全未知的全新配方预测时,XGBoost 模型表现惊艳,其拉伸模量(TM)的交叉验证 R^2 达到了 0.81,压缩模量(CM)的 R^2 更是高达 0.83。同时,结合 MAE 和 RMSE 等严苛指标的综合评测,证实了该工作流在“小样本、多参数”软物质工程预测中的极高稳定性和通用性。
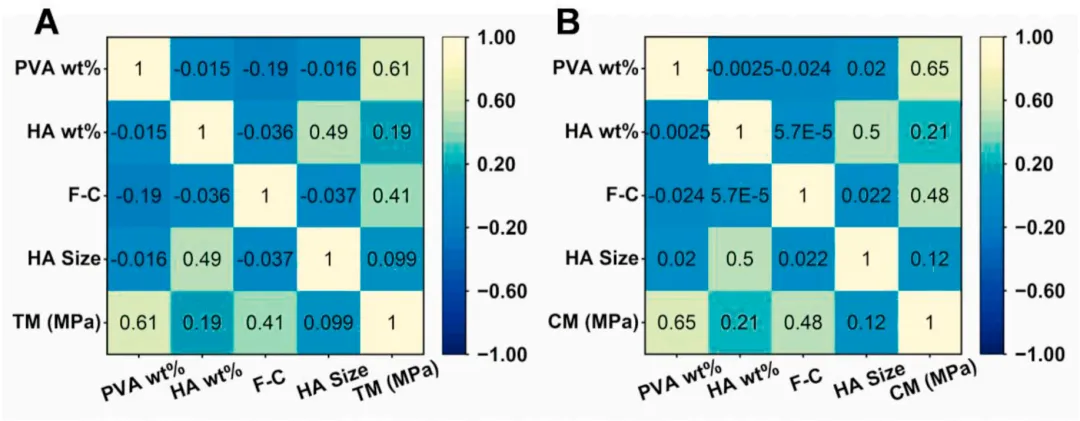
图3 (A、B)TM与CM的特征-属性相关性热图。
三、 白盒解密:SHAP + RSM 强强联合,量化水凝胶微观力学本质
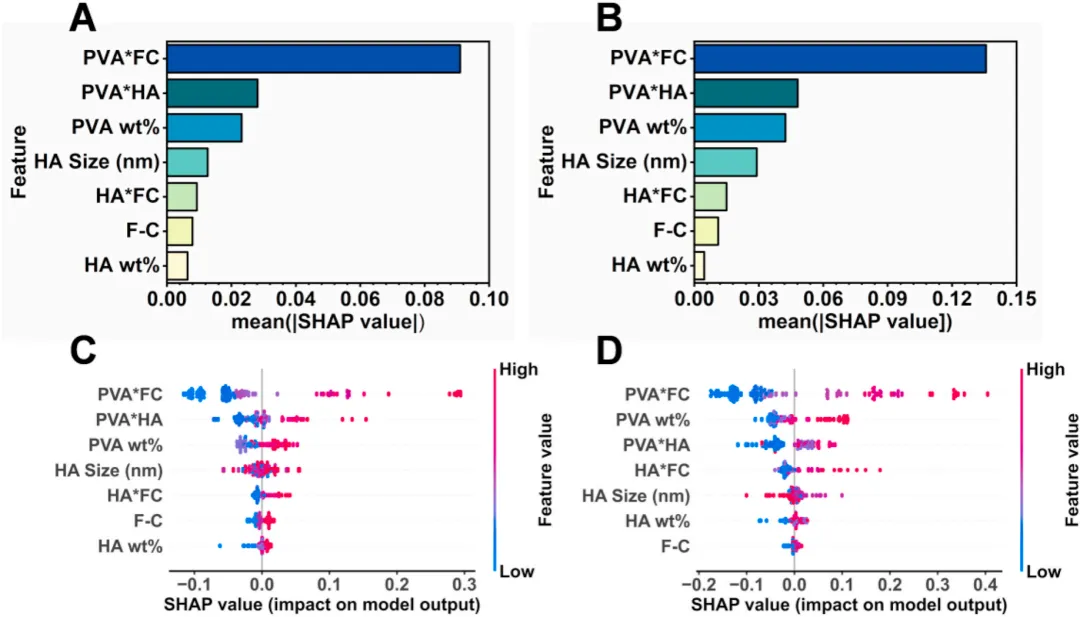
为了打破机器学习“黑盒模型”不可见、不可信的固有限制,团队创新地将基于合作博弈论的 SHAP 可解释性算法与传统统计学响应面模型(RSM)深度融合,首次对复合水凝胶内部各工艺参数的动态协同与竞争机制进行了定量拆解:
核心绝对主导:PVA与冻融循环的“协同密网”
SHAP定量归因表明,PVA浓度与冻融循环次数的交互作用是决定水凝胶力学强度的头号驱动力,分别主导了拉伸模量贡献的 40%~45% 和压缩模量贡献的 45%~50%。传统的扫描电镜(SEM)表征也同步证实:随着冻融次数的增加,水凝胶内部微观结构会发生由松散多孔向致密、连续三维骨架的稳步演进,从而大幅强化载荷传递。
非线性双刃剑:羟基磷灰石(HA)的“最佳增强窗口”
模型敏锐地捕捉到了无机增强相 HA 独特的非线性阈值特征。在 0~10 wt% 的低中浓度范围内,刚性的 HA 颗粒能够均匀分散并附着在聚合物孔壁上,起到局部承载、促进界面应力传递的积极增强作用。然而,一旦 HA 含量进一步飙升至 15 wt%,或者在基体 PVA 浓度过低时,模量的增长会剧烈放缓甚至发生陡降。
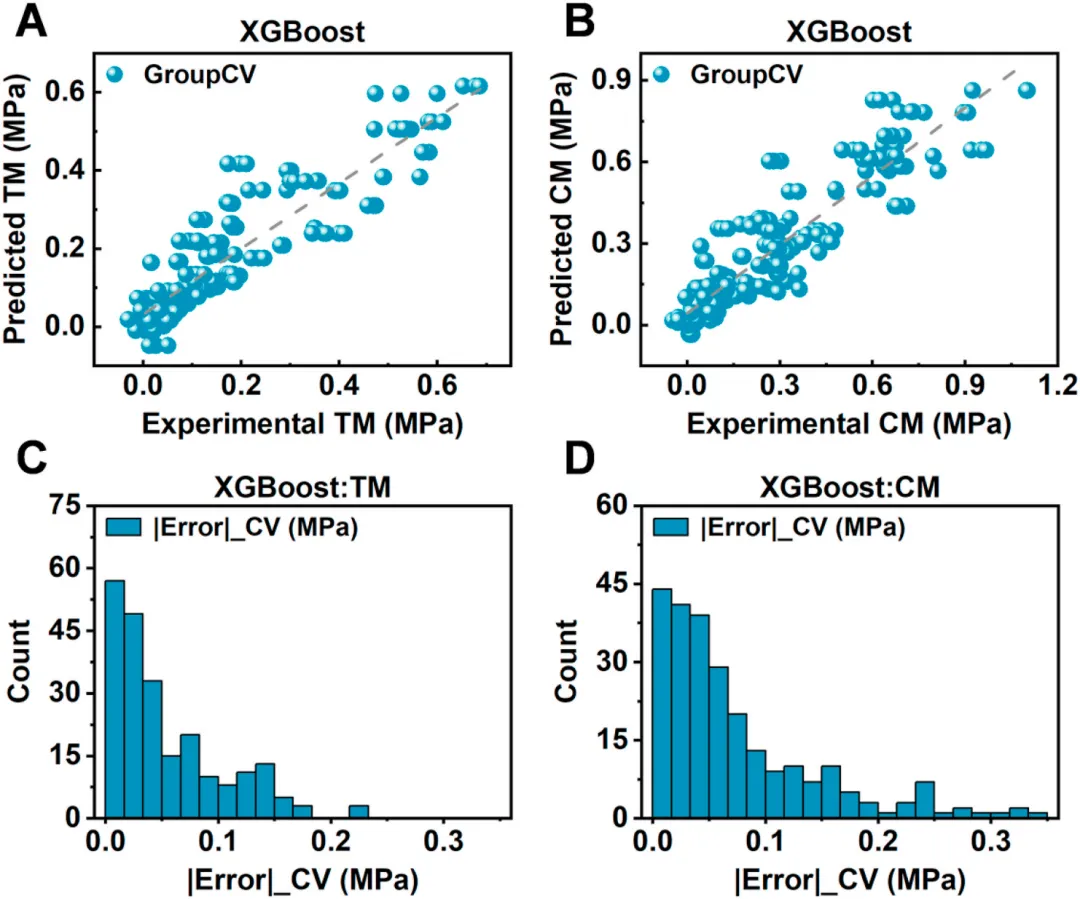
图4 (A)各模型预测TM和CM的决定系数(R²);(B、C)测试集中TM与CM预测误差的小提琴图;(D、E)测试集中实验值与模型预测值的逐点对比;(F、G)TM与CM绝对GroupKFold预测误差的经验累积分布函数。
为了探寻这一物理本质,团队利用高保真的冷冻扫描电镜(Cryo-SEM)及能谱分析(EDS)进行微观印证,完美阐明了其背后的双重复杂失效机制:一是过量 HA 易引发局部高浓度团聚,形成缺陷效应导致应力集中;二是高浓度的无机相会严重阻碍 PVA 分子链段的有序排布与结晶,干扰了原本靠物理交联/氢键建立起来的致密网络,从而引发力学性能的折损。
图5 (A、B)散点图展示了通过配方分组的GroupKFold交叉验证获得的PVA/HA水凝胶拉伸模量(TM)和压缩模量(CM)的预测值与实验值。样品特征由四个配方/工艺变量决定,即PVA含量、HA含量、HA颗粒尺寸以及冻融循环次数,具体详见表1。(C、D)所有验证折叠中TM和CM绝对预测误差的分布情况。
四、 闭环赋能:从主动搜索到靶向验证,开启理性设计新 Paradigm
在本项研究的闭环阶段,团队并未止步于理论预测,而是利用构建的“白盒”高精度 ML 模型,对未知的广阔参数连续空间进行了主动设计搜索,筛选推荐了多组潜在的最佳候选配方。随后,团队在实验室中开展了严谨的靶向“盲测”实验,其实测结果与 AI 预测值展现出了极高的一致性,圆满完成了“数据-模型-释义-验证”的完整学术闭环。
图6 (A、B)基于Shap方法得出的TM与CM全局特征重要性排序;(C、D)TM与CM的Shap蜂群图,其中FC表示冻融循环次数。
该工作不仅成功为 PVA/HA 复合水凝胶的精确性能调控与敏捷制造构建了坚实的数字底座,更为更广泛的“高维、小样本、强耦合”聚合物无机杂化生物材料的设计提供了一种极具工程参考价值、可高效复制的全新 AI for Science 理性范式。
论文信息:
Chuang Zhang, Weiwei Lan*, Shijie Ding, Jun Li, Junchao Wei*, Di Huang*, Weiyi Chen. Machine learning-assisted interpretable and leakage-resistant prediction of PVA/HA hydrogel mechanical properties under small-sample conditions. Polymer, 2026, 356: 130084.
论文链接(DOI):https://doi.org/10.1016/j.polymer.2026.130084